Bước đầu để tìm hiểu về SEO, bạn cần tìm hiểu được Crawl là gì và cách để trang web của bạn được đưa lên trang tìm kiếm của Google (SERPs). Để giải đáp cho các bạn về những vấn đề này, hãy cùng các chuyên gia đến từ HP Digi cùng đi sâu và phân tích về tính năng Crawl của các công cụ trên internet ngày nay.
Tổng quan về Crawl là gì
Crawl là một thuật ngữ vô cùng quan thuộc với các chuyên gia SEO. Và đây cũng là tính năng cần được tìm hiểu và tối ưu trước tiên khi bạn bắt đầu một chiến dịch SEO.
Crawl là gì?
Crawl trong SEO là quá trình mà các bot của công cụ tìm kiếm (thường được gọi là web crawlers hoặc spiders) tự động truy cập và phân tích nội dung trên các trang web. Mục đích của quá trình này là thu thập thông tin từ các trang web để cập nhật dữ liệu cho công cụ tìm kiếm.
Crawl giúp công cụ tìm kiếm hiểu cấu trúc và nội dung của website, từ đó quyết định trang nào cần được lập chỉ mục (index) để hiển thị trên kết quả tìm kiếm.
Google Crawl là gì?
Google Crawl cụ thể là quá trình Google sử dụng các bot của mình, được gọi là Googlebot, để truy cập và quét nội dung trên các website. Googlebot hoạt động dựa trên các liên kết giữa các trang web, bắt đầu từ danh sách URL được cung cấp qua các công cụ như Google Search Console, sitemap hoặc từ các liên kết trên các trang web khác.

Các bot này xác định nội dung nào cần thu thập, ưu tiên dựa trên giá trị của từng URL và sử dụng các tệp như robots.txt hoặc thẻ meta để điều hướng quá trình crawl.
Vai trò của giai đoạn Crawl là gì?
Crawl đóng vai trò cực kỳ quan trọng trong chiến lược SEO, vì nó là bước đầu tiên trong quy trình làm việc của công cụ tìm kiếm để xác định, thu thập và hiểu nội dung từ các trang web.
Khám phá và cập nhật nội dung mới
Crawl giúp công cụ tìm kiếm khám phá các trang mới được tạo hoặc nội dung đã cập nhật trên website. Khi các bot tìm thấy nội dung mới, chúng sẽ crawl dữ liệu để quyết định có nên đưa trang đó vào chỉ mục (index) không, từ đó đảm bảo thông tin hiển thị trên kết quả tìm kiếm luôn được cập nhật.
Hỗ trợ lập chỉ mục và xếp hạng trang web
Crawl là tiền đề để lập chỉ mục, giúp các công cụ tìm kiếm phân tích nội dung của từng trang. Sau khi lập chỉ mục, trang web có cơ hội được xếp hạng trong kết quả tìm kiếm dựa trên nội dung và giá trị của nó đối với người dùng. Nếu một trang không được crawl, nó sẽ không xuất hiện trên kết quả tìm kiếm.
Quản lý và tối ưu hóa Crawl Budget
Crawl budget là số lượng URL mà công cụ tìm kiếm sẽ crawl trong một khoảng thời gian nhất định. Việc tối ưu hóa crawl giúp tập trung tài nguyên vào các trang quan trọng, giảm lãng phí vào các trang không cần thiết hoặc kém chất lượng, từ đó cải thiện khả năng xếp hạng của toàn bộ website.

Đảm bảo cấu trúc website thân thiện với SEO
Crawl giúp phát hiện các vấn đề về cấu trúc website, chẳng hạn như lỗi 404, chuyển hướng vòng lặp, hoặc nội dung trùng lặp. Khi các vấn đề này được sửa chữa, hiệu suất SEO tổng thể của trang web sẽ được cải thiện, đồng thời tăng khả năng crawl và index hiệu quả.
Cung cấp dữ liệu để tối ưu hóa nội dung
Thông qua quá trình crawl, công cụ tìm kiếm thu thập thông tin về cách nội dung được tổ chức, liên kết nội bộ và mức độ liên quan của từng trang. Dữ liệu này không chỉ giúp công cụ tìm kiếm hiểu rõ hơn về trang web mà còn cho phép các quản trị viên website tinh chỉnh nội dung và cấu trúc để đạt hiệu quả tốt hơn.
Phát hiện và giảm thiểu các vấn đề bảo mật
Crawl cũng có thể phát hiện các tệp hoặc trang nhạy cảm vô tình bị lộ (chẳng hạn qua robots.txt hoặc URL mở). Việc kiểm tra crawl thường xuyên giúp bảo vệ thông tin quan trọng và giảm nguy cơ bị khai thác bởi các bot độc hại.
Tăng khả năng tiếp cận với người dùng
Crawl hiệu quả đảm bảo rằng nội dung quan trọng của bạn xuất hiện trước đúng đối tượng mục tiêu trên công cụ tìm kiếm. Điều này trực tiếp ảnh hưởng đến lưu lượng truy cập, trải nghiệm người dùng, và doanh thu từ các chiến lược SEO.
Những yếu tố ảnh hưởng đến khả năng Google Crawl là gì?
Để tối ưu được khả năng Crawl của Google Bot (Google Spider), bạn cần lưu ý đến những yếu tố sau. Tất cả đều là những yếu tố quan trọng tác động trực tiếp đến cách mà thuật toán Google nhìn nhận Website của bạn.
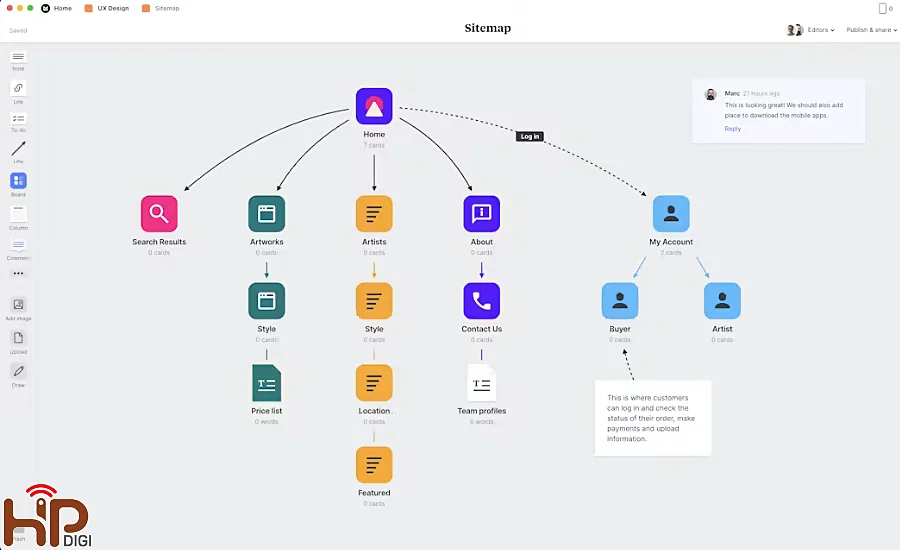
Cấu trúc trang web
- Kiến trúc trang web: Một cấu trúc rõ ràng, hợp lý với liên kết nội bộ tốt sẽ giúp bot của Google dễ dàng di chuyển qua các trang. Các trang nằm gần trang chủ hoặc được liên kết rõ ràng sẽ được ưu tiên hơn.
- Sơ đồ trang web (sitemap): Sơ đồ trang được thiết kế tốt, như XML sitemap, giúp Google hiểu trang nào quan trọng để ưu tiên crawl. Nếu sơ đồ trang chứa quá nhiều trang không quan trọng hoặc lỗi 404, sẽ làm lãng phí crawl budget.
Chất lượng nội dung
- Nội dung gốc và chất lượng cao: Bot Google ưu tiên các nội dung có giá trị, tổ chức tốt, và phù hợp với nhu cầu người dùng. Nội dung trùng lặp hoặc ít giá trị sẽ bị giảm ưu tiên crawl hoặc index.
- Thẻ canonical: Sử dụng thẻ canonical đúng cách để hướng bot đến phiên bản nội dung chính, tránh lãng phí thời gian crawl vào nội dung trùng lặp.
Hiệu suất kỹ thuật
- Tốc độ tải trang và hiệu suất máy chủ: Nếu máy chủ chậm hoặc thường xuyên gặp lỗi, Google có thể giảm tốc độ crawl. Tối ưu hóa máy chủ và giảm thời gian tải trang là cần thiết để duy trì crawl rate tốt.
- Liên kết hỏng và vòng lặp chuyển hướng: Các lỗi như liên kết hỏng hoặc vòng lặp chuyển hướng khiến bot lãng phí tài nguyên, làm giảm số lượng trang được crawl.
Quản lý robots.txt và thẻ meta
- Tập tin robots.txt: Chỉ định chính xác trong robots.txt các trang nên và không nên được crawl để tối ưu hóa sử dụng crawl budget.
- Thẻ meta noindex: Sử dụng đúng các thẻ noindex để chỉ ra những trang không cần thiết phải được index, giúp bot tập trung vào nội dung quan trọng.
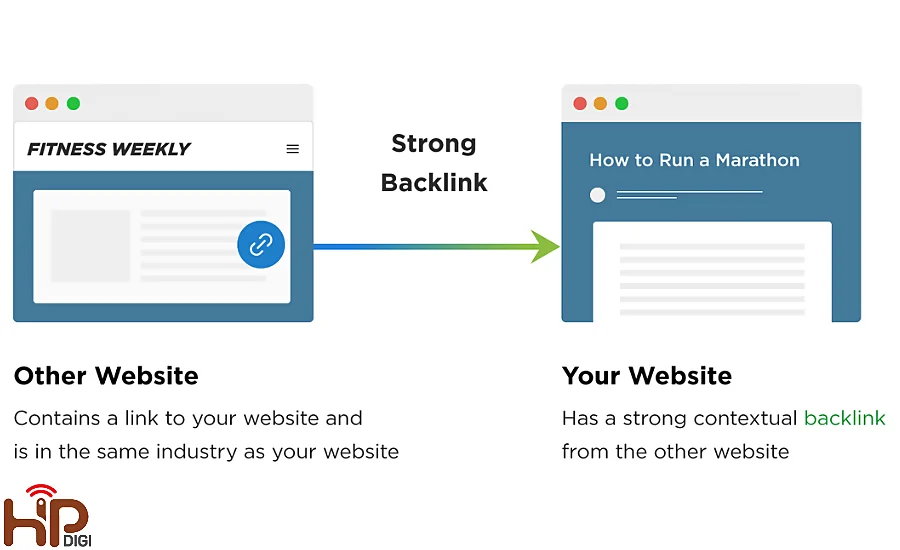
Liên kết trỏ về trang (Backlinks)
Trang có nhiều liên kết ngược chất lượng cao sẽ được Google ưu tiên crawl hơn. Bởi lẽ, các backlink này cung cấp cho Google tín hiệu tích cực về mức độ quan trọng của trang đó.
Tần suất cập nhật nội dung
Google sẽ ưu tiên crawl các trang được cập nhật thường xuyên với nội dung mới hoặc thay đổi đáng kể. Điều này khuyến khích các chuyên gia về quản trị website liên tục thay đổi và cập nhật nội dung cho trang web của mình.
Cách để tối ưu cho Google Bot Crawl là gì?
Sau khi nắm được những yếu tố quan trọng tác động đến khả năng Crawl của Google Bot. Bạn cần tập trung tìm hiểu và tối ưu những yếu tố này sao cho phù hợp với yêu cầu của thuật toán Google.
Tăng tốc độ tải trang và hiệu năng website
Tốc độ tải trang không chỉ ảnh hưởng đến trải nghiệm người dùng (UX) mà còn quyết định số lượng URL mà Googlebot có thể thu thập trong một phiên làm việc. Bạn có thể tối ưu hóa bằng cách đầu tư vào máy chủ chất lượng cao, hỗ trợ giao thức HTTP/2 để xử lý nhiều yêu cầu URL cùng lúc.
Hạn chế các chuỗi chuyển hướng (redirect chains) giúp bot không lãng phí thời gian xử lý các đường dẫn không cần thiết. Đồng thời, tối ưu mã nguồn HTML, CSS, và JavaScript để loại bỏ các đoạn mã dư thừa, giảm dung lượng tệp tải xuống, và sử dụng các công cụ như Google PageSpeed Insights để cải thiện các chỉ số Core Web Vitals.
Quản lý nội dung chất lượng thấp
Googlebot ưu tiên các trang nội dung có giá trị, và bạn nên loại bỏ hoặc cải thiện nội dung chất lượng thấp để giảm cạnh tranh không cần thiết cho ngân sách crawl. Các trang bị lỗi 404, trùng lặp, hoặc lỗi noindex cần được sửa hoặc xóa.
Những trang không cần thiết cho SEO nên được chặn bằng tệp robots.txt hoặc sử dụng thẻ meta noindex một cách hợp lý. Ngoài ra, hãy duy trì nội dung luôn mới và giá trị để thu hút Googlebot trở lại thường xuyên hơn.
Sử dụng sơ đồ trang web (XML Sitemap) hiệu quả
Sơ đồ trang web giúp hướng dẫn Googlebot đến những URL quan trọng nhất. Đảm bảo sơ đồ chỉ bao gồm các URL có thể lập chỉ mục và có giá trị SEO. Cập nhật thường xuyên các thẻ <lastmod> để báo hiệu khi có nội dung mới.
Đừng quên gửi sơ đồ trang web lên Google Search Console và đưa đường dẫn vào tệp robots.txt để đảm bảo bot truy cập nhanh chóng. Điều này giúp tối ưu hóa quá trình thu thập thông tin và tăng khả năng lập chỉ mục cho nội dung quan trọng.
Kiểm soát các chỉ dẫn lập chỉ mục
Các thẻ meta như rel=canonical và noindex cần được sử dụng đúng cách để tránh lãng phí crawl budget. Hãy kiểm tra kỹ các URL được loại trừ trong báo cáo Google Search Console để xác định nguyên nhân và tối ưu hóa lại nếu cần thiết.

Nếu có các URL tương tự, hãy hợp nhất hoặc xóa bỏ nội dung không cần thiết bằng các mã trạng thái 301 hoặc 410 thay vì 404.
Tối ưu liên kết nội bộ và backlinks
Liên kết nội bộ giúp Googlebot dễ dàng khám phá các trang mới hoặc sâu hơn trong cấu trúc website. Hãy đảm bảo rằng các trang quan trọng được liên kết từ nhiều nơi trên site.
Đồng thời, xây dựng backlinks từ các trang web uy tín để tăng cường hiệu quả crawl của Googlebot và giúp bot ưu tiên lập chỉ mục các nội dung này.
Bằng cách tối ưu hóa các yếu tố trên, bạn không chỉ cải thiện hiệu quả crawl mà còn nâng cao khả năng xếp hạng cho trang web trên Google.
Lựa chọn đơn vị uy tín để tiến hành chiến dịch SEO
Trong các công việc của một chuyên viên SEO, việc tối ưu khả năng Crawling của Google không phải là một chuyện đơn giản. Chính vì vậy, doanh nghiệp không nên cố tự mình tối ưu nếu không có kinh nghiệm.
Nếu quý khách cần một đơn vị cung cấp những giải pháp SEO toàn diện và uy tín, hãy liên hệ ngay đến địa chỉ liên lạc của HP Digi để được đội ngũ chúng tôi tư vấn và giải đáp một cách nhanh chóng.
- Địa chỉ công ty: Tầng 7, Số 9 Phố Dịch Vọng Hậu, Phường Dịch Vọng Hậu, Quận Cầu Giấy, Hà Nội
- Hotline: +84 375 885 886
- Email dịch vụ: info@hpdigi.vn
Quy trình để Google Bot Crawl là gì?
Để triển khai quy trình thu thập dữ liệu (Crawl), Google Bot sẽ cần thực hiện những bước như sau.
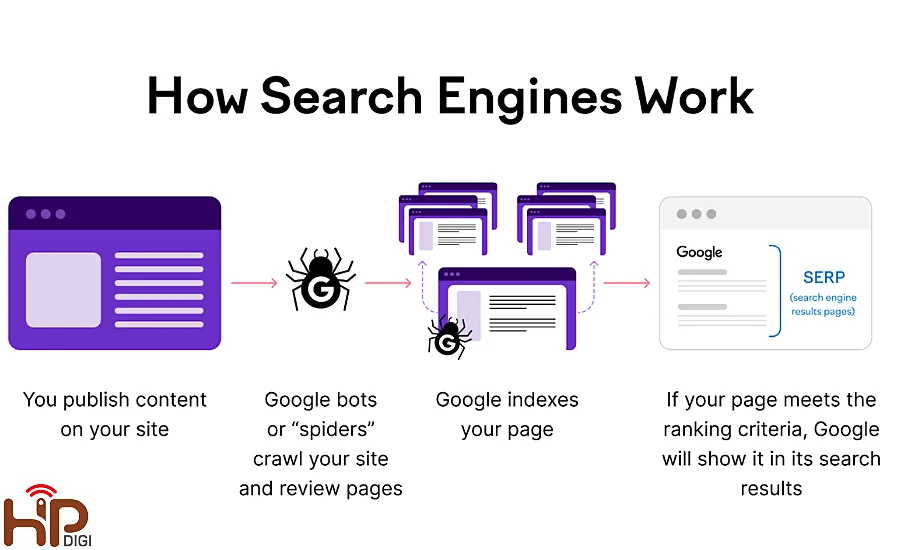
Bước 1. Phát hiện nội dung (Discovery Phase)
Googlebot bắt đầu việc Crawl bằng việc xác định các URL mới thông qua nhiều cách khác nhau, bao gồm:
- Dữ liệu từ sitemap: Các trang web cung cấp tệp sitemap XML để chỉ dẫn cho Googlebot biết các URL cần thu thập.
- Theo dõi liên kết (Link Following): Googlebot theo dõi các liên kết từ các trang web đã được lập chỉ mục để phát hiện thêm URL mới.
- Tín hiệu từ Google Search Console: Các chủ sở hữu website có thể yêu cầu Googlebot crwal data từ trang cụ thể thông qua Google Search Console.
Bước 2. Tải và phân tích nội dung (Fetching Phase)
Googlebot gửi yêu cầu tới máy chủ của trang web để tải HTML và các tài nguyên liên quan (như hình ảnh, CSS, JavaScript):
- Tối ưu hóa tải xuống: Sử dụng giao thức HTTP/2 để tăng tốc độ giao tiếp.
- Đánh giá robots.txt: Trước khi tải trang, Googlebot kiểm tra tệp robots.txt để đảm bảo trang hoặc phần nội dung không bị chặn.
Bước 3. Xử lý và phân tích dữ liệu (Processing Phase)
- Sau khi tải xuống, Googlebot xử lý nội dung HTML, phát hiện các liên kết mới và các yếu tố quan trọng như tiêu đề, thẻ meta, và cấu trúc nội dung.
- Các trang có nội dung động như JavaScript hoặc AJAX có thể được xử lý để đảm bảo nội dung đầy đủ được lập chỉ mục.
Bước 4. Lập chỉ mục (Indexing Phase)
- Sau khi phân tích, nội dung trang được thêm vào cơ sở dữ liệu của Google. Quá trình này xác định cách nội dung hiển thị trong kết quả tìm kiếm.
- Googlebot ưu tiên lập chỉ mục cho các trang có nội dung chất lượng, dễ truy cập, và cấu trúc tốt.
Bước 5. Cập nhật và làm mới (Refreshing Phase)
- Googlebot quay lại trang định kỳ dựa trên mức độ thay đổi của nội dung hoặc độ phổ biến của trang.
- Tần suất thu thập phụ thuộc vào tín hiệu từ trang (ví dụ: nội dung thường xuyên cập nhật sẽ được ưu tiên thu thập thường xuyên hơn).
Mối quan hệ giữa Google Index và Crawl là gì?
Crawl và Google Indexing có mối liên hệ chặt chẽ và mật thiết với nhau. Sự kết hợp của hai công đoạn này sẽ quyết định vị trí của trang web trên các công cụ tìm kiếm.
Index là gì?
Index là bước tiếp theo, trong đó dữ liệu thu thập được từ quá trình crawl sẽ được lưu trữ trong cơ sở dữ liệu khổng lồ của Google. Trong quá trình này, các thông tin như nội dung, từ khóa, thẻ meta, và cấu trúc trang sẽ được phân tích để quyết định mức độ liên quan và giá trị của trang đó đối với các truy vấn tìm kiếm.
Mối quan hệ giữa Crawl và Index
- Tính phụ thuộc: Một trang cần được crawl trước khi có thể được index. Nếu Googlebot không thể truy cập hoặc phát hiện trang, trang đó sẽ không được thêm vào chỉ mục của Google.
- Sự loại bỏ: Không phải tất cả các trang được crawl đều được index. Ví dụ, những trang có nội dung trùng lặp, chất lượng kém hoặc bị chặn bởi tệp robots.txt có thể bị loại khỏi chỉ mục.
- Tầm quan trọng đối với SEO: Nếu trang của bạn không được index, nó sẽ không hiển thị trên kết quả tìm kiếm, bất kể nội dung có chất lượng đến đâu. Do đó, đảm bảo khả năng crawl và index tốt là rất quan trọng để tăng thứ hạng trên công cụ tìm kiếm.
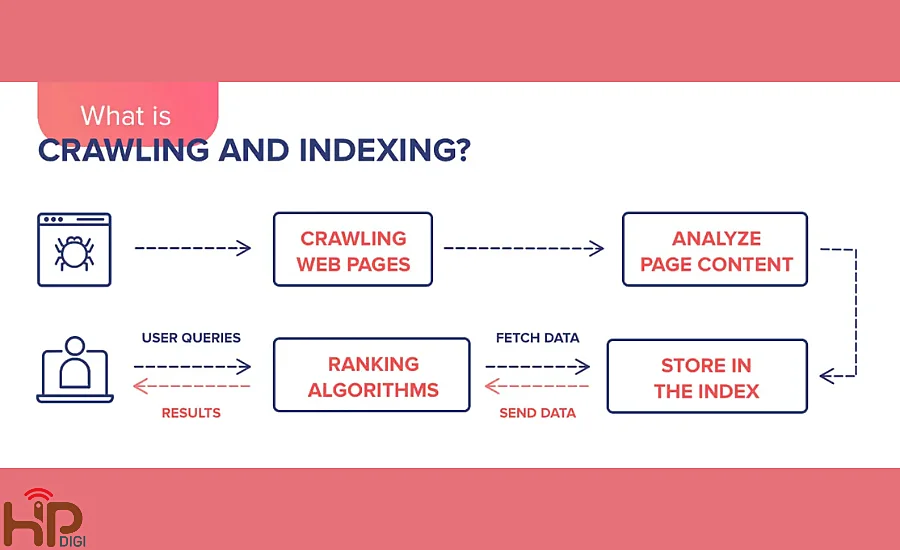
Việc tối ưu hóa cho cả hai khía cạnh này giúp cải thiện khả năng hiển thị nội dung của bạn trong trang kết quả tìm kiếm (SERPs). Điều này bao gồm việc xây dựng cấu trúc liên kết nội bộ mạnh mẽ, tạo sitemap XML, và cập nhật nội dung thường xuyên để Googlebot dễ dàng truy cập và hiểu nội dung trang web.
Làm thế nào để tối ưu Crawl Budget?
Mỗi Website đều sở hữu một Crawl Budget giới hạn. Các nhà quản trị cần phân bổ chúng một cách tối ưu để giúp Google index chính xác những nội dung gia trị trên trang Web.
Tối ưu Crawl Budget cho Website Thương mại điện tử
- Ngăn Googlebot crawl các URL không quan trọng: Sử dụng tệp robots.txt để chặn các trang bộ lọc, tìm kiếm nội bộ, hoặc các tham số không cần thiết.
- Tập trung vào sản phẩm và danh mục chính: Đảm bảo nội dung quan trọng như trang sản phẩm phổ biến, danh mục chính được crawl trước.
- Canonical Tag: Sử dụng thẻ canonical để giải quyết vấn đề trùng lặp nội dung giữa các phiên bản URL khác nhau.
- Liên kết nội bộ hiệu quả: Sử dụng liên kết nội bộ giữa các sản phẩm liên quan và danh mục chính để Googlebot dễ dàng di chuyển qua website.
- Kiểm tra lỗi crawl: Xác định và sửa các lỗi như 404 hoặc redirect loop trong báo cáo Crawl Stats của Google Search Console.
Website Blog
- Tập trung vào nội dung quan trọng: Sử dụng liên kết nội bộ để ưu tiên các bài viết có giá trị cao, như bài viết đang xếp hạng hoặc được chia sẻ nhiều.
- Xóa hoặc redirect nội dung cũ không cần thiết: Redirect các bài viết lỗi thời hoặc không liên quan đến nội dung mới hơn.
- Cập nhật và làm mới bài viết: Thường xuyên cập nhật các bài viết cũ để Googlebot có lý do crawl lại.
- Sitemap hiệu quả: Chỉ đưa các bài viết chất lượng cao và URL đang hoạt động vào sitemap XML.
- Kiểm tra URL được index: Sử dụng Google Search Console để đảm bảo chỉ các bài viết cần thiết được index.
Website Doanh nghiệp Địa phương
- Thách thức:
- Số lượng trang ít hơn so với thương mại điện tử hoặc blog, nhưng cần đảm bảo thông tin địa phương được ưu tiên crawl.
- Cách tối ưu hóa:
- Tập trung vào trang chính và trang liên quan đến địa phương:
Đảm bảo trang chủ, trang liên hệ, và trang thông tin địa phương (Google My Business, địa chỉ, đánh giá) được crawl đầu tiên. - Sử dụng dữ liệu cấu trúc (Structured Data):
Áp dụng schema markup như LocalBusiness hoặc Organization để giúp Google hiểu nội dung. - Đồng bộ hóa thông tin trên tất cả các trang:
Thông tin như địa chỉ, giờ làm việc, và số điện thoại cần được cập nhật đồng nhất để tránh lãng phí Crawl Budget vào thông tin cũ. - Sitemap đơn giản:
Sitemap nên liệt kê rõ các trang quan trọng như dịch vụ, chi nhánh, hoặc các bài viết blog liên quan đến địa phương. - Liên kết nội bộ:
Kết nối các trang liên quan (như chi nhánh khác hoặc dịch vụ địa phương) để cải thiện khả năng crawl.
- Tập trung vào trang chính và trang liên quan đến địa phương:
Các loại Bot Crawl là gì?
Hiện nay, có nhiều công cụ hoặc ứng dụng có khả năng Crawl dữ liệu từ các trang web trên Internet. Những loại Crawl Bot này được sinh ra để phục vụ nhiều mục đích khác nhau, kể cả tích cực lẫn tiêu cực.
Search Engine Crawlers (Bot tìm kiếm)
Đây là loại phổ biến nhất, được sử dụng bởi các công cụ tìm kiếm như Googlebot, Bingbot, hoặc Baidu Spider. Chúng khám phá và thu thập thông tin từ các trang web để xây dựng chỉ mục phục vụ tìm kiếm.
Ví dụ: Google Bot, Bing Bot, Yandex Bot
Commercial Crawlers (Bot thương mại)
Được sử dụng bởi các nền tảng SEO và phân tích như Screaming Frog, Ahrefs, hoặc Moz. Các bot này giúp doanh nghiệp theo dõi liên kết, phân tích nội dung và cải thiện thứ hạng SEO.
Ví dụ: Screaming Frog, Ahrefs Bot, Moz Bot
Data Mining Crawlers (Bot khai thác dữ liệu)
Các bot này thu thập dữ liệu lớn cho nghiên cứu hoặc kinh doanh, thường được sử dụng trong phân tích thị trường, đánh giá cảm xúc, hoặc tổng hợp nội dung.
Ví dụ: Common Crawl, Data Miner
Web Archiving Crawlers (Bot lưu trữ)
Như Internet Archive’s Wayback Machine, các bot này thu thập và lưu trữ nội dung trang web theo thời gian để tạo ra các bản lưu trữ lịch sử.
Ví dụ: Internet Archive’s Wayback Machine
Focus/Specialized Crawlers (Bot chuyên dụng)
Các bot được thiết kế cho nhiệm vụ cụ thể như thu thập danh sách việc làm, so sánh giá sản phẩm, hoặc kiểm tra thông tin bảo mật.
Ví dụ: Jobbot, PriceSpider

Malicious Crawlers (Bot ác ý)
Những bot này được sử dụng cho mục đích không hợp pháp như thu thập dữ liệu trái phép, phát tán spam hoặc khai thác lỗ hổng bảo mật.
Ví dụ: Scrapy (malicious use)
API Crawlers (Bot tương tác API)
Các bot này thu thập dữ liệu từ API, thay vì các trang web, thường dùng để truy cập dữ liệu từ mạng xã hội hoặc dịch vụ trực tuyến.
Ví dụ: Twitter Bot, Facebook Graph API
Các lỗi thường gặp khi Google Bot Crawl là gì?
Googlebot, giống như các bot crawler khác, có thể gặp phải một số vấn đề khi cố gắng truy cập và thu thập thông tin từ website. Hiểu và giải quyết các lỗi crawl này là rất quan trọng để đảm bảo rằng website của bạn được lập chỉ mục đầy đủ và có thể xếp hạng trên công cụ tìm kiếm.
Lỗi Máy chủ (5xx)
Các lỗi này cho thấy có vấn đề từ phía máy chủ, chẳng hạn như máy chủ không hoạt động, cấu hình sai hoặc quá tải. Ví dụ, lỗi 500 Internal Server Error hoặc 503 Service Unavailable có nghĩa là máy chủ không phản hồi yêu cầu. Những vấn đề này thường yêu cầu kiểm tra nhật ký máy chủ và có thể cần nâng cấp dung lượng máy chủ hoặc tối ưu hóa cấu hình máy chủ.
Lỗi 404 (Không tìm thấy)
Lỗi này xảy ra khi trang yêu cầu không còn tồn tại. Điều này có thể do trang bị xóa, URL bị thay đổi hoặc có lỗi gõ liên kết. Một số lượng lớn lỗi 404 có thể làm giảm hiệu quả của việc crawl. Cách khắc phục là thiết lập redirect 301 hoặc đảm bảo trang được khôi phục nếu cần thiết.

Lỗi Soft 404
Lỗi soft 404 xảy ra khi một trang hiển thị giống như lỗi 404 (không tìm thấy), nhưng không trả về mã trạng thái HTTP chính xác. Điều này có thể gây nhầm lẫn cho Googlebot và ảnh hưởng đến quá trình crawl. Giải pháp là đảm bảo rằng các trang không tồn tại phải trả về mã lỗi chính xác 404 hoặc 410.
Lỗi Redirect
Khi có quá nhiều chuyển hướng (redirect chain) hoặc chuyển hướng vòng lặp (redirect loop), Googlebot sẽ bị “kẹt” và không thể lập chỉ mục trang đúng cách. Cần đơn giản hóa các chuyển hướng và loại bỏ những chuỗi hoặc vòng lặp không cần thiết.
Bị chặn bởi Robots.txt
Đôi khi, Googlebot có thể không crawl được một số trang vì tệp robots.txt chặn chúng. Nếu điều này không phải là cố ý, tệp robots.txt cần được cập nhật để cho phép Googlebot crawl các trang cần thiết.
Vấn đề bảo mật
Mã độc hoặc các cuộc tấn công phishing có thể khiến Googlebot chặn truy cập vào website của bạn. Việc kiểm tra bảo mật định kỳ và loại bỏ các nội dung độc hại là những bước cần thiết để ngăn ngừa vấn đề này.
Sự khác biệt giữa Web Scraping và Web Crawl là gì?
Hiện nay, có hai khái niệm thường bị hiểu lầm chính là Scraping và Crawling. Tuy rằng cách vận hành của chúng có phần giống nhau nhưng mục tiêu quy mô lại khác biệt đáng kể.
Web Scraping là gì?
Web Scraping Là quá trình tự động thu thập dữ liệu cụ thể từ một trang web nhất định, như thông tin sản phẩm, giá cả, bài viết, hay bất kỳ loại dữ liệu nào mà người dùng yêu cầu.
Scraping sẽ trích xuất dữ liệu từ HTML của trang web và lưu trữ nó trong các định dạng như JSON, CSV hay Excel, phục vụ cho các mục đích phân tích hay ứng dụng máy học.
Đây là một hoạt động nhắm vào việc lấy dữ liệu chính xác và có chủ đích, thay vì quét toàn bộ trang web như crawler.
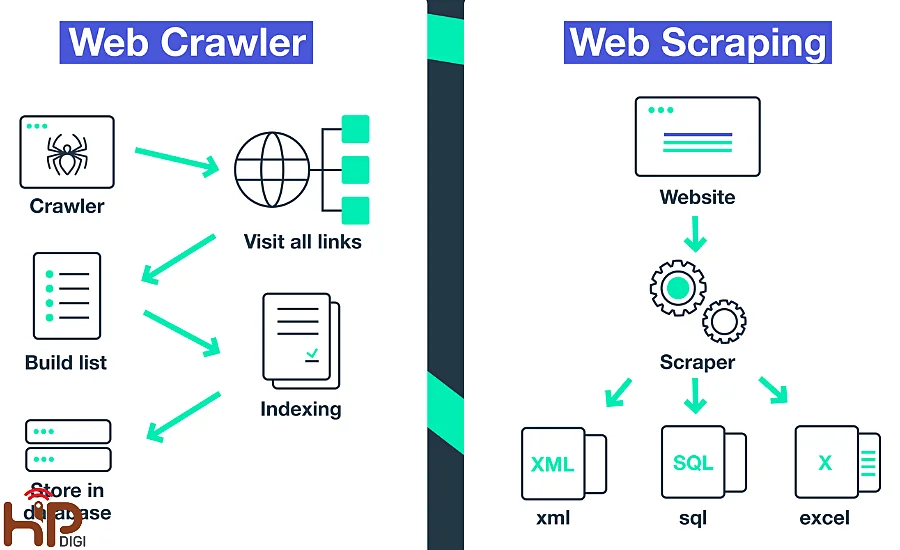
Các điểm khác biệt chính giữa Scraping và Crawl là gì?
- Mục đích sử dụng: Crawling chủ yếu được sử dụng để khám phá và lập chỉ mục các trang web (Googlebot, ví dụ), trong khi scraping chủ yếu dùng để thu thập thông tin cụ thể từ một trang web.
- Dữ liệu thu thập: Crawling thu thập dữ liệu chung từ toàn bộ trang, trong khi scraping chỉ trích xuất những phần dữ liệu xác định.
- Công cụ: Các công cụ như Scrapy có thể dùng cả để crawling và scraping, nhưng các thư viện như BeautifulSoup và Selenium thường được dùng cho web scraping, trong khi Heritrix và Apache Nutch chuyên cho web crawling.
Những câu hỏi thường gặp về Crawl là gì?
Crawl Budget là gì?
Crawl Budget là số lượng các trang mà Googlebot có thể crawl trên website của bạn trong một khoảng thời gian nhất định. Điều này phụ thuộc vào các yếu tố như chất lượng của website, số lượng trang và khả năng máy chủ.
Việc tối ưu hóa crawl budget giúp Googlebot có thể duyệt trang nhanh chóng và hiệu quả hơn, tránh lãng phí tài nguyên vào các trang không cần thiết.
Làm sao để kiểm tra lỗi crawl của website?
Bạn có thể sử dụng Google Search Console để theo dõi các lỗi crawl trên website. Công cụ này sẽ thông báo nếu có lỗi như 404 (trang không tìm thấy), lỗi máy chủ 5xx, hay các vấn đề khác làm gián đoạn quá trình crawl. Điều này giúp bạn nhanh chóng nhận diện và sửa chữa các vấn đề ảnh hưởng đến SEO.
Crawl có ảnh hưởng đến SEO không?
Có, việc Googlebot crawl trang của bạn là một yếu tố quan trọng trong việc xếp hạng trên Google. Nếu Googlebot không thể crawl hoặc gặp lỗi khi cố gắng duyệt qua trang của bạn, những trang này sẽ không được đưa vào chỉ mục và không thể xếp hạng trên kết quả tìm kiếm.

Làm sao để tối ưu hóa Crawl cho website của mình?
Để tối ưu hóa quá trình crawl, bạn cần đảm bảo rằng cấu trúc website rõ ràng và dễ duyệt, không có lỗi 404 hay các trang trùng lặp. Bạn cũng nên tối ưu hóa tốc độ tải trang và giảm thiểu các trang không cần thiết. Sử dụng các công cụ như Google Search Console để theo dõi và sửa các lỗi crawl là rất quan trọng.
Crawl Budget có thay đổi không nếu website mở rộng nội dung?
Có, Crawl Budget sẽ thay đổi. Khi website mở rộng nội dung, Googlebot sẽ phân bổ lại Crawl Budget dựa trên:
- Độ lớn của website: Số lượng URL tăng lên đồng nghĩa với việc Googlebot cần nhiều tài nguyên hơn để crawl.
- Chất lượng và mức độ ưu tiên nội dung: Google ưu tiên crawl các nội dung giá trị cao hoặc thường xuyên cập nhật.
- Tài nguyên máy chủ (Server): Nếu tài nguyên server bị giới hạn, Google có thể điều chỉnh Crawl Budget để tránh quá tải.
Làm sao để biết Googlebot có truy cập trang của mình?
Bạn có thể kiểm tra sự truy cập của Googlebot bằng những cách như sau.
- Google Search Console: Xem báo cáo “Crawl Stats” trong mục “Settings” để biết số lượng yêu cầu crawl và loại nội dung được crawl.
- Tệp nhật ký máy chủ (Server Logs): Xem các log truy cập để tìm các yêu cầu từ Googlebot (User-Agent: Googlebot).
- Sử dụng công cụ kiểm tra URL: Trên Google Search Console, kiểm tra trạng thái index của URL hoặc yêu cầu Googlebot crawl lại.
Crawl ảnh hưởng đến hiệu suất SEO trong bao lâu?
Crawl ảnh hưởng đến SEO ngay sau khi Googlebot hoàn tất việc crawling và gửi nội dung đến hệ thống index.
Thời gian hiệu lực: Từ vài giờ đến vài ngày, tùy thuộc vào mức độ ưu tiên của nội dung trên website và tần suất crawl của Googlebot đối với trang.
Ví dụ, nội dung quan trọng hoặc cập nhật thường xuyên (tin tức, blog nổi bật) sẽ được xử lý nhanh hơn.
Khi nào cần tối ưu hóa lại Crawl Budget?
Bạn cần tối ưu hóa Crawl Budget khi trang Web của bạn nằm trong những trường hợp như sau.
- Website lớn: Khi số lượng URL tăng đáng kể (thêm danh mục, bài viết, hoặc sản phẩm mới).
- Crawl không hiệu quả: Khi nhiều URL không quan trọng hoặc bị lỗi được crawl (kiểm tra trong báo cáo “Crawl Stats” của Google Search Console).
- Tài nguyên bị giới hạn: Khi server gặp quá tải hoặc thời gian phản hồi tăng do Googlebot.
- Thay đổi cấu trúc website: Khi di chuyển, hợp nhất, hoặc phân tách nội dung, đảm bảo Googlebot ưu tiên crawl URL chính xác.
Lời kết
Qua bài viết trên, HP Digi đã giải đáp cho các bạn câu hỏi Crawl là gì, và những tư vấn từ chuyên gia để tới ưu khả năng Crawl cho trang web của bạn. Hy vọng những thông tin trên cùng các kiến thức bên lề có thể hỗ trợ các bạn trong việc đưa trang web của mình lên những vị trí cao trên trang tìm kiếm Google.